This post was produced as an assignment for Paul Waddell‘s Fall 2018 CP 255 class at UC Berkeley. It’s kind of a joke. But I remain convinced that these pet datasets could be profitably mined.
UPDATE, 4/25/2022: CARTO, the company which hosted these maps, insisted on me paying $299 per month to keep them online. Since, per above, they were kind of a joke, I have replaced them with videos instead.
Where is the data from and how did you acquire it?
These data, encoded geographically by Forward Sortation Area (the first three digits in a Canadian postal code), are from Toronto’s Municipal Licencing and Standards department. Toronto makes it available through their Open Data Catalogue at this page; I downloaded the five years of continuous data, from 2013 to 2017, and joined them to this FSA shapefile from the Statistics Canada website to represent them on the map.
What is the data about and why is it interesting?
Toronto’s Animal Services department enforces licencing requirements for dogs and cats living in the city, renewed annually. Each dog and cat in the city is supposed to wear a tag with its licence information, to assist in returning animals home when they enter the shelter system. Fees generate revenue which funds the operations of the local shelter system. These data lay out the geographical distribution of pets, and I was interested to understand how the concentration of pets varied across the city.
It struck me, upon finding this dataset, that pet ownership could be an indicator of household types by area—places with more pets might have more single-family homes, better access to open space, or perhaps a preponderance of fire hydrants. It would also logically inform operational planning for Animal Services; if an area has an unusually high number of pets, they may want to prioritize the locations of their facilities to address that need pre-emptively. Furthermore, the change in pet numbers by area over time could suggest changes in the makeup of a given neighbourhood—more pets might mean more young families; fewer pets might mean structural changes in a neighbourhood.
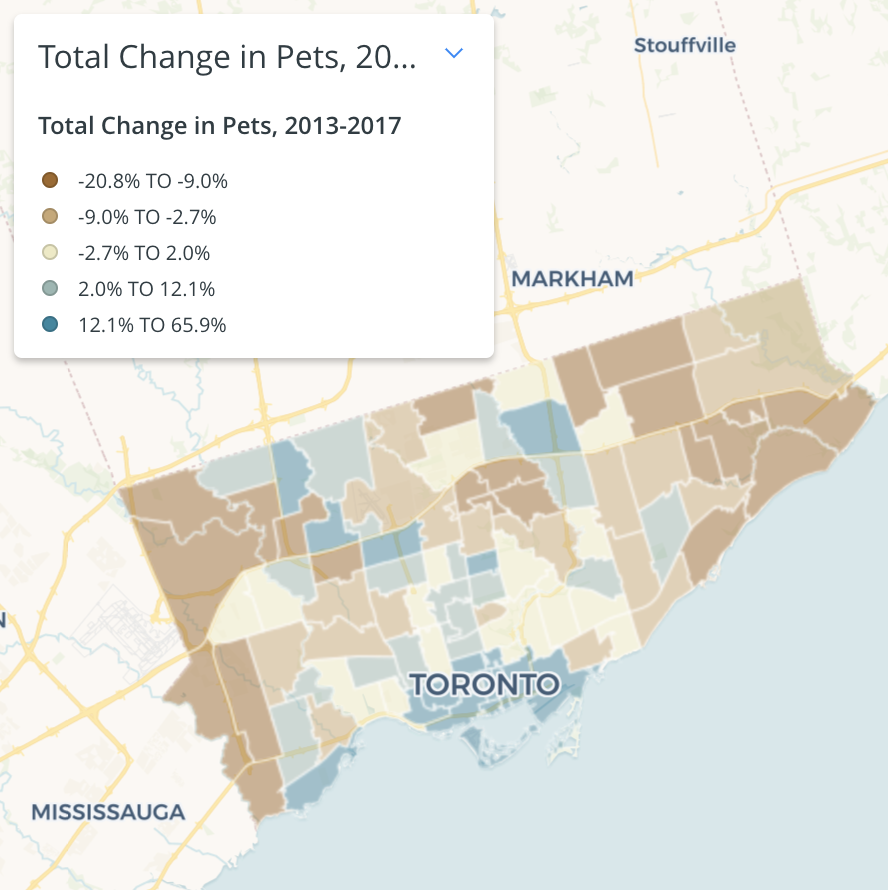
What stories do your maps tell?
Toronto has a notably uneven distribution of pets across the city. The downtown core is clearly beige in the first map, indicating a lack of pets, with concentrated pet populations in the more traditionally suburban neighbourhoods to its east and west. But the map showing change over time presents an interesting counter-narrative: pet populations are growing the fastest in the downtown core and in some parts of North York. By configuring the embedded widgets, a viewer can understand the difference between cats and dogs by neighbourhood; they have broadly similar distributions, although there are significantly more licenced dogs than cats in the city. Also of note—the far western and eastern parts of the city have experienced the most dramatic declines in pet ownership, which may suggest a broader restructuring of those neighbourhoods.
Who is your audience and how can they benefit from these visualizations?
I see two audiences for these maps.
First, Toronto’s Animal Services could use them to their benefit, as the geographic distribution of the pet population is most germane to their planning processes. By understanding where there are cats and dogs in the city, they can more effectively design their operations—it doesn’t make sense, say, to have crews based in the downtown core or in the city’s northwestern reaches, where there are fewer pets than East York or Etobicoke. Visualizing the change over time adds a wrinkle which could help them predict service demand in the future: with significant growth in the dense downtown neighbourhoods, there may be future demand to contend with.
Second, planners could use these maps to begin to understand how pet ownership is changing in Toronto, and how they should meet owners’ needs. Where should we build new off-leash dog parks, or install pet-washing stations? These data could also serve as a proxy for neighbourhood change, especially over time. If the distribution of pets is changing, so might the households with these pets—there might be more young people getting dogs for their downtown apartments, or families might be moving into existing denser neighbourhoods with their cats.
Why are these visualizations important or useful?
I think these are more of a starting point than an absolute result. I have been curious about the ways pets are distributed in the city, given the investments Toronto has made in building dog runs across many of the city’s larger parks, but also because there are specific neighbourhood characters that pet ownership reflects. My old neighbourhood, Leslieville—mapping roughly to FSAs M4M and M4L—was reputed as a place to move when you’re starting a family, and buy a dog to practice before having a child. It might conjure an image of a stroller-pushing dad with a golden retriever on a leash, depending on who you ask.
But pet ownership does have more meaning than just reputation—it reflects the structure, design, density, and human population of a neighbourhood. If you’re living in an apartment complex—say, in one of the dense towers in Thorncliffe Park, FSA M4H—you might not be allowed to have a pet due to your landlord’s rules, or you might not have access to parks to walk your dog through. I think that these data could serve as an interesting research topic, particularly given the wide range of percentage changes across the city. The sociological nature of these changes is worth interrogating.
Explain your process creating these maps with Carto: what did you do, what design decisions did you make, and why?
Before I settled on the pet data shown, I decided to import some data on contributions to city councillors’ campaigns into Carto. It was encoded by postal code, which could present an interesting, granular view to the distribution of donors, which would make an interesting heat map. Unfortunately, Carto does not handle Canadian geographic data well natively—it can only work at the FSA level. I hunted through Toronto’s Open Data Catalogue for interesting data encoded by FSA, and stumbled across these datasets. Importing them, Carto gave me a point-based distribution, which was too sparse to be interestingly interpreted.
So I sought out the shapefile of FSAs which Statistics Canada produced, thinking it would let me more accurately represent the differences by neighbourhood. By playing with the shapefile and my analysis in QGIS, I was able to join and create a more traditional choropleth map, which helped to close the detail gap I faced with the point-based representations. From there, the formatting and design decisions were straightforward—Carto unfortunately made it difficult to present a time-series animation of the data I had, given the way it was structured, so I settled on neatly colour-coded population and change maps, with toggles to show some of the detail on cats and dogs. Ideally, these would be more detailed at the geographical level—and we could see, say, a point-based distribution of all the cats and dogs in the city—but alas, for today, the higher-level view is what makes sense.
1 comment